Create an image for this
A clean technical architecture diagram for an "OR Assistant" - a hands-free conversational intra-operative AI system for operating theatres. The diagram shows two main phases: LEFT SIDE - "Phase 1: Pre-OT Knowledge Base Population": Documents (evidence/guidelines, surgical texts, patient records/labs/imaging) flow into an "Unsiloed" document parser, then get chunked and embedded, then stored in "MOSS" vector database with metadata tags (source, type, date, patient_id). CENTER/RIGHT SIDE - "Phase 2: Intra-OT Runtime" with two parallel planes: TOP PLANE - "Logging Plane (always-on)": LiveKit (real-time AV) receives OR audio/video → Speech-to-Text → Logger (timestamps & persists events) → loops back continuously. Labeled as async/batched. BOTTOM PLANE - "Query Plane (on demand)": Triggered by surgeon voice query OR complication flag → LiveKit STT captures query → Context Assembly (query + recent log context) → MOSS Search (filtered by type & patient_id) → LLM reasoning → MiniMax TTS voice response + React UI (shows answer, source citation, confidence score). Has a "Refusal" path when confidence is too low. BOTTOM SECTION - "Guardrails": Source attribution (every answer cites chunk source), Confidence threshold (numerical score shown to surgeon), Hallucination guard (no answer if not grounded), Sterility guard (no physical actions). Style: Dark background (deep navy/charcoal), glowing accent colors (teal for data flow, orange for voice/audio paths, purple for AI/LLM components, green for outputs). Clean sans-serif fonts, rounded boxes, clear arrows showing data flow direction. Modern medical tech aesthetic. Title "OR Assistant Architecture" at top.
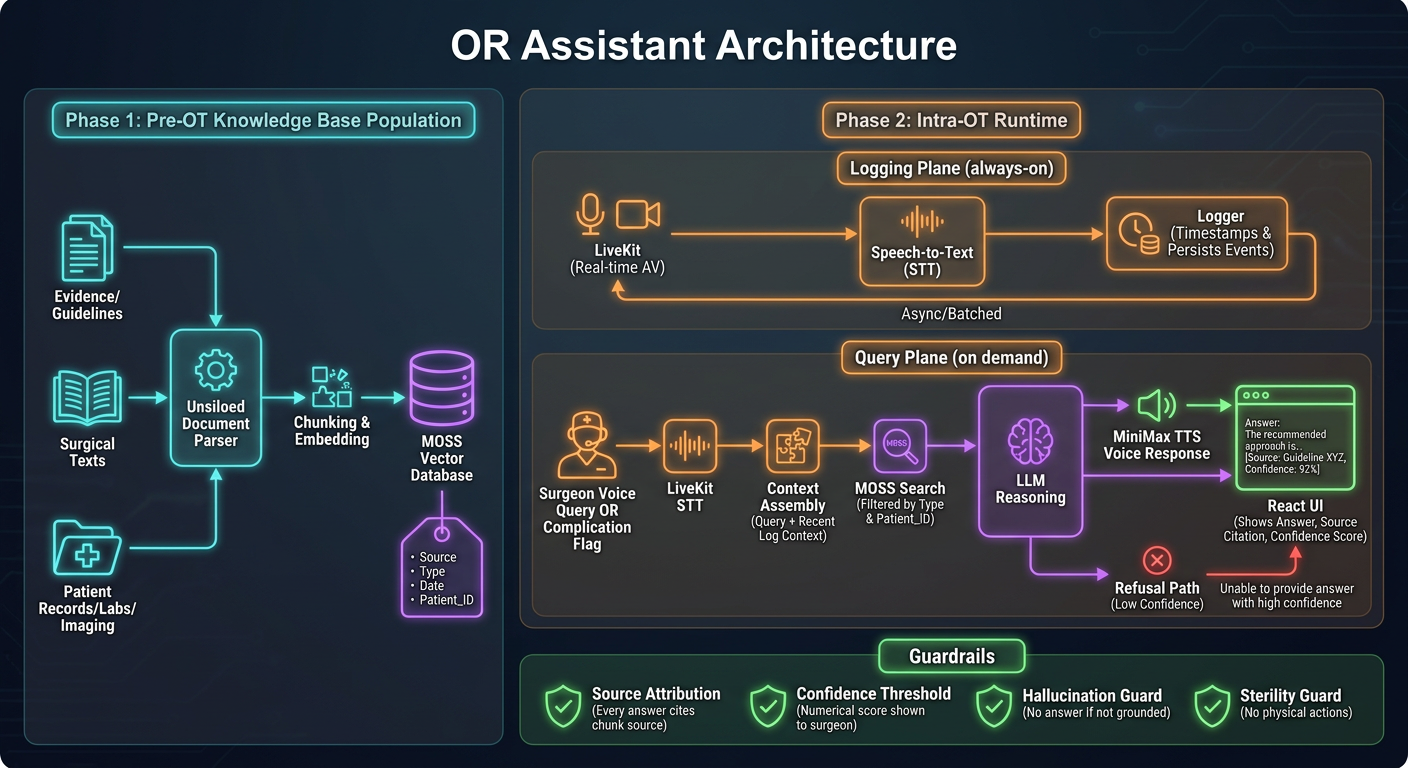
- Phase 1 (Pre-OT) on the left showing the ingestion pipeline: documents → Unsiloed parser → chunk/embed → MOSS vector DB
- Phase 2 (Intra-OT) on the right with the two parallel planes:
- Logging Plane (always-on, async): LiveKit → STT → Logger loop
- Query Plane (on-demand): voice trigger → context assembly → MOSS search → LLM → MiniMax TTS + React UI
- Guardrails at the bottom (source attribution, confidence threshold, hallucination guard, sterility guard)